환영합니다, Rolling Ress의 카루입니다.

오늘은 두 번째 결과물을 제작하는 시간입니다. 지난번에 예고한 대로, 이번에는 보고서를 작성하는 게 아니라 여러분께서 직접 인공지능 모델을 제작해보는 시간을 가질 겁니다. 더브레인 구글 드라이브에 이런 파일이 숨겨져 있는데, 여러분껜 보이지 않을 겁니다. 복붙 방지용입니다.

여러분의 개별 폴더 내에는 여러분께서 주신 .csv 파일과 3000 XXX_2차시 회귀분석.ipynb라는 파일이 있을 겁니다. 여러분 개별로 생성해드렸는데, 내용은 모두 똑같아요.


우리가 그동안 이론으로만 배웠던 선형 회귀(Linear Regression), K-최근접 이웃 회귀(k-Nearest Neighbors Regression)등을 실제로 구현해보며 시각화할 겁니다. 사탐방 때 했던 회귀분석과는 상당히 다를 거예요. 그건 뭐 버튼 몇 번만 누르면 끝났으니까. 근데 이건 모든 것들을 여러분이 직접 해야 합니다.
# 회귀 모델: K-최근접 이웃 회귀, 선형 회귀
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import LinearRegression
# 훈련 데이터와 테스트 데이터 나눠주는 거, 그리드 서치 (하이퍼파라미터 튜닝)
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
# 창문해 때 지겹도록 썼던 matplotlib
import matplotlib.pyplot as plt
# numpy 배열, pandas, csv 리더
import numpy as np
import pandas as pd
import csv첫 번째 빈칸은 이렇게입니다. 필요한 모듈을 import 하면 됩니다.

그리고 csv 파일을 읽을 겁니다. 이때 여러분이 회귀분석에 사용할 인덱스가 필요한데, 이걸 보고 작성하시면 됩니다. 만약 IHDI와 Loss%로 회귀를 할 거라면 2와 4가 되겠네요. 인덱스는 0부터 시작합니다.
이후부터는 제 설명에 따라 진행해주세요.
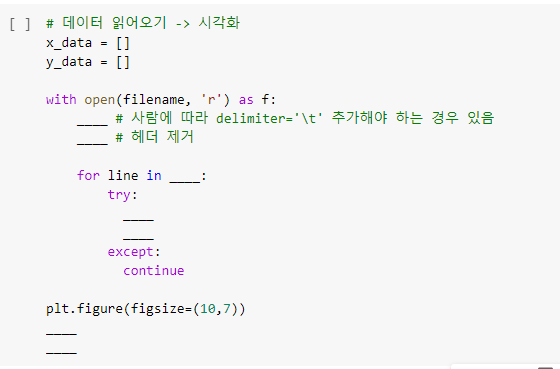
데이터를 읽어온 뒤, matplotlib으로 그리는 작업을 할 겁니다.

그 후 하이퍼 파라미터 튜닝을 위해 반복해서 모델을 훈련시킬 겁니다.
근데 사실 이 둘, numpy와 그리드 서치를 이용하면 순식간에 끝납니다. 이 얘기도 할 거예요.
트리 알고리즘 빼고 나머지 회귀분석을 모두 진행할 겁니다. 본 글에서는 여기까지만 소개할테니, 나머지는 현장 강의를 들어주세요. 감사합니다 :)
'고양국제고 > 더브레인' 카테고리의 다른 글
| [더브레인-3] 2. 워드클라우드 예제 실습 안내 (0) | 2022.07.07 |
|---|---|
| [더브레인-3] 1. 정규표현식 예제 실습 안내 (0) | 2022.07.07 |
| 더브레인 1차 결과물 소개 (0) | 2022.06.01 |
| [더브레인] 4월 진행 상황 (0) | 2022.04.19 |
| [더브레인] 머신러닝을 통한 뉴스 기사 댓글 혐오 표현 분석 (0) | 2022.04.14 |