환영합니다, Rolling Ress의 카루입니다.
** 3-5. 기사 요약 [통계]
이건 통계 분야이긴 한데, 난이도가 조금 높습니다. 대신 재밌는 구경거리가 많아요. 약간 언어와 통계 분야의 난이도를 맞추기 위해서.. 언어 친구들이 5, 5, 5, 5로 갈려나간다면 여러분들은 3, 3, 10 정도로.
!pip install pyLDAvis
from nltk.corpus import stopwords
from sklearn.datasets import fetch_20newsgroups
from gensim import corpora
from gensim.summarization.summarizer import summarize
import pandas as pd
import nltk
import gensim각설하고, 필요한 모듈부터 불러줍시다. nltk는 자연어 처리 모듈인데, 여기서는 gensim이라는 모듈을 추가로 사용합니다.
# 기사 번호
ARTICLE_NO = 1
# 불용어 다운로드
nltk.download('stopwords')
documents = fetch_20newsgroups(shuffle=True, remove=('headers', 'footers', 'quotes')).data
print(f'Got {len(documents)} samples.')
print(documents[ARTICLE_NO])
news_df = pd.DataFrame({'document': documents})
# 알파벳이 아닌 모든 문자를 제거합니다.
news_df['clean_doc'] = news_df['document'].str.replace(r'[^a-zA-Z]', ' ')
# 길이가 3 초과인 단어만 가져옵니다.
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>3]))
# 소문자로 변환합니다.
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: x.lower())
news_df['clean_doc'][ARTICLE_NO]뉴스 기사를 갖고 와서 자연어 처리를 위한 정제를 거칩니다. 특수문자를 모두 제거하고, 짧은 단어를 제거하고, 대문자를 모두 소문자로 바꾸는 과정입니다. 그리고, ARTICLE_NO의 숫자를 적절히 바꿔보세요. (0~10) 불러 온 기사 중 해당 기사를 가지고 분석하게 됩니다.
# 불용어를 받아오고 토큰화시킨 뒤, 불용어를 제거합니다.
stop_words = stopwords.words('english')
tokenized_doc = news_df['clean_doc'].apply(lambda x: x.split())
tokenized_doc = tokenized_doc.apply(lambda x: [item for item in x if item not in stop_words])
print(tokenized_doc[ARTICLE_NO])
# 뉴스에서의 단어 인베딩과 빈도수를 기록합니다.
dictionary = corpora.Dictionary(tokenized_doc)
corpus = [dictionary.doc2bow(text) for text in tokenized_doc]
print(corpus[ARTICLE_NO])문장을 분석하는데 크게 도움이 되지 않는 '불용어'를 제거합니다. 나머지는 주석에 쓰인 설명대로입니다. 정제한 뉴스 기사 데이터를 바탕으로 코퍼스(말뭉치)를 만들고, 이것의 출력 결과를 보여줍니다.
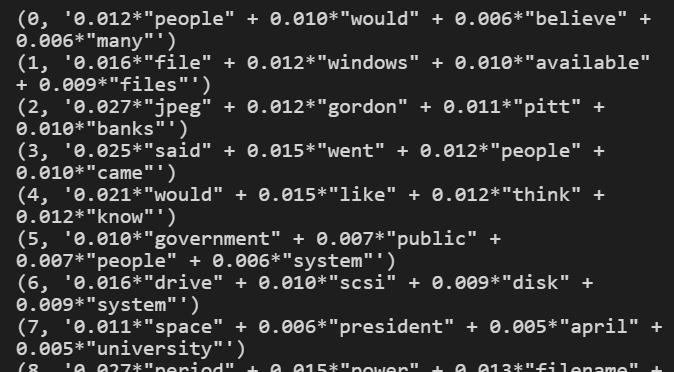
# 20개의 토픽, k=20
NUM_TOPICS = 20
# corpus를 가지고 lda모델 학습 num_topics은 토픽의 개수 , passes는 알고리즘의 동작 횟수
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = NUM_TOPICS, id2word=dictionary, passes=15)
# 학습한 lda모델의 토픽별 핵심 단어 확인, num_words 는 단어의 개수
topics = ldamodel.print_topics(num_words=4)
# 결과 출력
for topic in topics:
print(topic)여기는 그냥 이 알고리즘이 어떻게 분석을 했는지 알아보는 과정입니다. 출력 결과가 아래처럼 이상하게 나올텐데, 크게 신경 쓰실 필요는 없어요. 그냥 '아 이렇구나' 하고 넘기시면 됩니다. 저도 몰라요.
article = '''
'''
print(summarize(article, word_count = 15))이번 글의 하이라이트. article하고 저 따옴표들 사이에 여러분이 찾은 기사를 복붙해주세요.
article = '''
이스라엘이 오는 23일부터 실내 마스크 의무도 해제하기로 발표한 가운데 방대본은 "실외 마스크 착용 의무를 해제하더라도 실내 마스크는 상당 기간 착용 의무를 유지할 방침"이라고 강조했다.
김 팀장은 계절적으로 여름이 다가오는 가운데 문 닫고 에어컨을 이용하는 습관, 3밀 환경과 지하철·버스를 많이 이용하는 생활을 고려할 때 실내마스크 해제 "시기상조"라며 "굉장히 신중한 검토가 필요한 상황"이라고 말했다.
그는 "향후 실외 마스크를 해제하더라도 실내에서는 고위험군을 보호하고 유증상자 등 감염될 수 있는 분을 차단할 수 있도록 상당 기간 착용 권고할 예정"이라고 밝혔다.
'''이런 식으로요. (제목부터 긁어오셔야 합니다.) 물론 실제 기사는 이것보다 훨씬 길겠죠. 일단 넣고 돌리면, 알아서 요약을 해줍니다. word_count에 써진 숫자를 바꾸면 (15~30~50~100) 해당 단어 수로 요약을 해줍니다. 참고로 너무 작게 설정한 경우에는 그냥 무시하고 말이 되는 선에서 요약을 하니 참고하세요.
기사 요약이 끝났으면, 출력 결과를 캡처해서 드라이브에 올려주시기 바랍니다. 수고하셨습니다.
'고양국제고 > 더브레인' 카테고리의 다른 글
| [더브레인-3] 4. 한국어 토큰화 예제 실습 안내 (0) | 2022.07.07 |
|---|---|
| [더브레인-3] 3. 전산형태론 예제 실습 안내 (0) | 2022.07.07 |
| [더브레인-3] 2. 워드클라우드 예제 실습 안내 (0) | 2022.07.07 |
| [더브레인-3] 1. 정규표현식 예제 실습 안내 (0) | 2022.07.07 |
| 더브레인 2차 결과물 제작 안내 (ft. 파이썬&머신러닝) (0) | 2022.06.20 |