
이제 머신러닝을 어느 정도 했으니, 딥러닝으로 넘어가보자. tensorflow를 설치할 건데, 아래 명령어를 통해서 설치할 수 있다.
PS > pip install tensorflow설치가 완료되면 다시 주피터 노트북을 켠다. 참고로 이 과정들이 귀찮다면, 그냥 구글 코랩을 사용하면 된다. 이미 설치도 다 되어 있다. 어쨌든, 완료되면 맨 위의 코드를 실행한다.
전달받은 데이터를 확인해보면 뭔가 많다. 이건 흑백 사진이다. cmap에서 gray_r은 회색으로 하되, 이미지를 반전시키라는 뜻이다. 0은 검은색이고 255(0xFF)는 흰색이다. 그런데 0은 연산을 해봤자 곱해버리면 0이다. 배경보다 피사체에 집중하기 위해 일부러 색 정보를 반전시키는 것이다.
회색이 아니라 다른 계열로도 설정할 수 있다. 아무거나 넣어보면, 오류가 나면서 "이런 값들만 가능합니다." 라고 알려준다. 그 중에 하나를 넣어봤다. 열화상 카메라로 찍은 듯한 느낌이 든다.
이제 인공신경망에 대해 살펴보자. Input Layer, 입력층은 데이터 자체를 말한다. 이곳에서는 계산을 하지 않는다. 대신 은닉층, Hidden Layer에서는 본격적인 계산을 수행한다. 이건 좀 나중에 다시 설명하고, 출력층을 보자. 꼭 출력층이 하나의 결과로 나올 필요는 없다.
입력층의 각 동그라미들을 x1, x2, ...라고 하고, 출력층의 각 동그라미들을 z1, z2, ...라고 하자. 여기서부터가 중요하다. 출력층에 있는 요소 z1을 만들기 위해 x1에서는 가중치 w(1, 1)이 곱해지고, x2에서는 w(2, 1)이 곱해진다. 즉, 가중치는 w(x-number, z-number)로 나타낼 수 있다.
** 실제로는 w₁, ₂와 같이 아래첨자를 사용하지만, 편의상 w(1, 2)로 기술하겠습니다.
그렇게 곱한 값을 더하고, 마지막으로 절편을 더한다. b1. 그럼 z1이 완성된다. 멋지다. 우리는 이걸 뉴런이라고 부를 것이다. 유닛unit이라고 불러도 좋다.
import tensorflow as tf
from tensorflow import kerastensorflow는 구글에서 만든 딥러닝 lib이다. 딥러닝 lib들은 인공신경망을 위해 막대한 연산을 해야 한다. 이걸 CPU가 하고 있으면 미치고 환장하는 노릇이 생긴다. 생각해보자. 요즘 CPU 코어가 몇 개 달려서 나오는가? 뭐, 중급형을 생각해보면 라이젠은 6C12T, 인텔도 신형은 6P4E로 10C16T 구성을 가진다. 12스레드, 잘해야 16스레드. 뭐... AMD의 스레드리퍼도 128스레드가 최대다. 한 번에 동시에 작업할 수 있는 작업의 수, 128. 택도 없다.
그래서, 텐서플로에선 GPU를 적극적으로 활용한다. 가상화폐 채굴도 GPU가 맡는데, 이유는 비슷하다. 병렬 작업에 훨씬 유리하기 때문이다. RTX 3060만 해도 쿠다코어가 3584개, 3090 Ti는 10752개에 달한다. 10752와 128. 어느 쪽이 유리한가.
이해가 안 될 수 있다. 당연하다.
예를 들어, 이런 문제가 있다고 해보자.
규칙이 없는 자연수의 합이다. 전체 항이 3000개 정도 있다고 해보자. 이걸 대학생 12명과 중학생 3000명(...)에게 각각 풀어보라고 한다. 어느 쪽이 빨리 끝나겠는가? 이게 뭐 별 대단한 연산도 아니고, 덧셈만 하면 되는, 아주 쉬운 연산이다. 중학생 3000쪽이 압도적으로 빨리 끝난다. 물론, 실수를 조금 할 수도 있다. 그런데 10000단위가 넘어가는 연산에서 100 미만의 차이는 그다지 크지 않다.
여하튼, 텐서플로에서는 Keras라는 front-end lib을 제공한다. back-end는 다른 라이브러리들인데, GPU연산을 실질적으로 수행한다.
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
print(f'train set 크기: {train_scaled.shape}, {train_target.shape}')
print('validation set 크기: {}, {}'.format(val_scaled.shape, val_target.shape))이제 시작해보자. 딥러닝에서는 validation set를 분리해서 사용한다. 교차 검증을 하기엔 시간이 너무 많이 걸린다. 처음에는 dense layer, 밀집층을 만들 것이다.
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))
model = keras.Sequential(dense)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
Dense(뉴런 개수, 출력 함수, 입력 크기)처럼 사용한다. 이진분류라면 굳이 softmax 함수를 사용할 필요 없이 sigmoid를 사용하면 된다. model은 지금 신경망을 담고 있다.
수학시간에 노가다를 뛰었던 이 활성화 함수... 드디어 얘를 이해한 듯 싶다. 각 뉴런에서는 앞 층의 가중치를 각각 곱한 뒤 더해, b 값을 합한다고 설명했다. 각 뉴런의 출력은 활성화함수를 지난다. activation function. 이건 층으로 보지 않는 게 일반적이지만, 때에 따라 다르다.
이진분류에서는 출력층 뉴런이 하나다. 아까 예시로 든 그림이 이진분류용 인공신경망이다. 이건 확률을 통해 양성인지 음성인지 판정할 수 있다. 시그모이드 함수가 { x | x는 실수 }를 정의역으로, { y | 0 < y < 1 }을 치역으로 가지니 전체 실수에 대해 확률로 만들 수 있다. 이진 분류의 출력 뉴런은 양성 클래스에 대한 확률만 출력하는데, 음성 샘플의 경우 강제로 타깃값을 1로 만들어 계산이 가능하게 한다. 타깃값이 ψ라 할때, 1-ψ를 계산하면 된다.
훈련 결과가 적당히 나왔다. 에포크를 반복할 때마다 정확도가 조금씩 향상되는 게 보인다. 손실도 조금씩 감소한다.
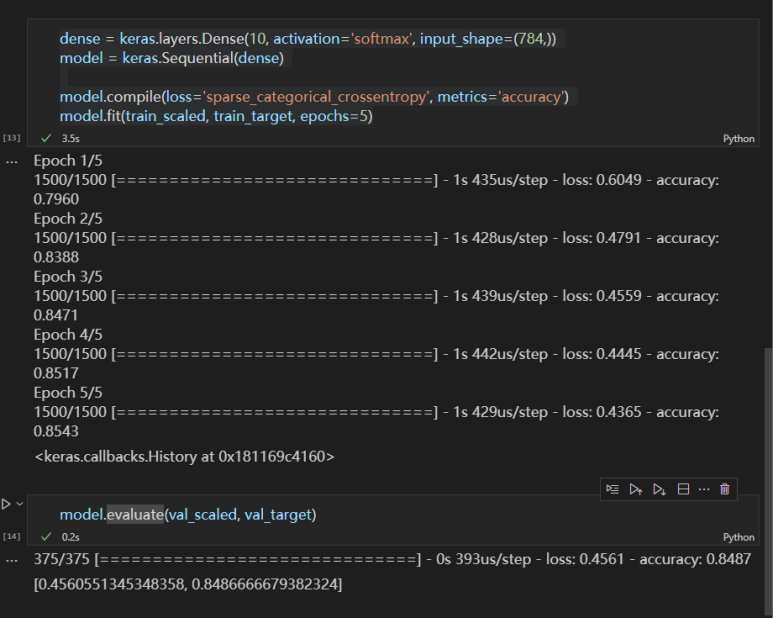
validation set을 통해 모델을 평가해본다. validation set이 train set에 비해 accuracy가 조금 떨어지는 게 정상이다.
이제 은닉층을 하나 추가할 것이다. 은닉층도 결국엔 출력층으로 값을 '출력'하기 때문에, 활성화 함수가 꽁무니에 따라붙는다. 다만 은닉층의 경우, ReLU 함수를 사용하기도 한다.

참고로 ReLU 함수는 위와 같이 생겼다.
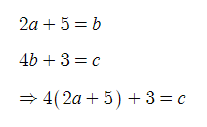
Hidden Layer에서 활성화 함수를 왜 사용할까? 단순히 이런 식을 생각해본다면, 한 문자에 대해 정리해서 다른 식에 대입해버리면 문자 하나가 소거된다. 이걸 막기 위해 Hidden Layer에서는 계산을 조금 꼬아줘야 한다.
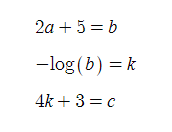
갑자기 log가 생겼다. 이건 뭐 어찌할 방법이 없다. 나름의 역할이 생긴 것이다.
# Hidden Layer: 100 neurons, actv func=sigmoid
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden')
# Output Layer: 10 neurons
dense2 = keras.layers.Dense(10, activation='softmax', name='output')일단 만들어보자. 그냥 층을 각각 형성해주면 된다.

뉴런의 집합을 구성했다. 왼쪽은 dense1, 은닉층이 될 부분이다. 오른쪽은 dense2, 출력층이 될 부분이다. 실제로는 오렌지색 뉴런은 100개, 파란색 뉴런은 10개가 있다. 이때, 은닉층의 경우 출력층의 뉴런보다 많아야 한다.
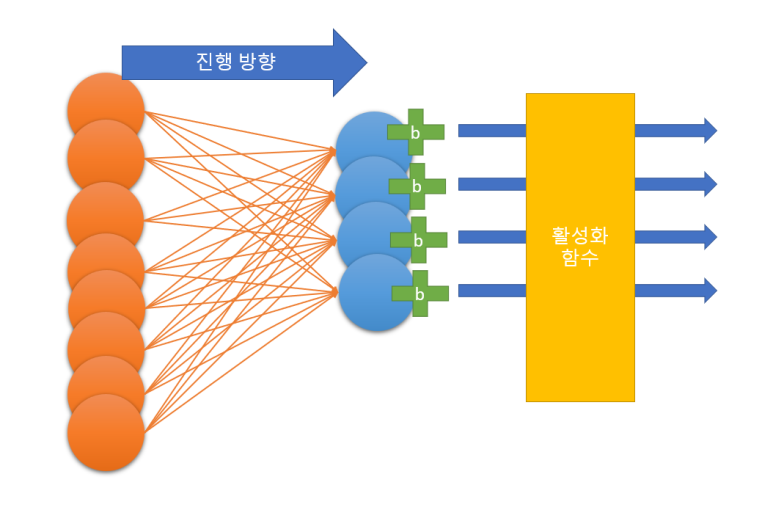
이제 뉴런을 연결시킬 것이다. 은닉층에서 출력층으로 가게끔 이으면 된다. 우리가 저 선을 일일이 그을 필요는 없다. 케라스가 알아서 해준다. 혹시 아까 설명이 이해가 안 됐던 분들을 위해. 각 뉴런에는 b값이 더해진다고 했다. 끝에서부터 선을 쭉 따라가면 그게 다 하나의 뉴런이다. 그러니, 파란 부분(출력층)만 봐도 된다. 값이 나오면, 활성화 함수를 통해 신경망 밖으로 나온다.
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='Fashion MNIST model')
# 확인용
print('인공신경망 모델 확인')
model.summary()사실, 위에서 만든 dense1, dense2 따위의 인스턴스는 사용할 일이 없다. 그러니, 생성자에 바로 넣어주자.
model = keras.Sequential(name='Fashion MNIST model')
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'))
model.add(keras.layers.Dense(10, activation='softmax', name='output'))
# 확인용
print('인공신경망 모델 확인')
model.summary()아니면 그냥 add 메서드를 사용해도 된다. 어느쪽이어도 상관 없으니, 편한 쪽으로 하자.
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
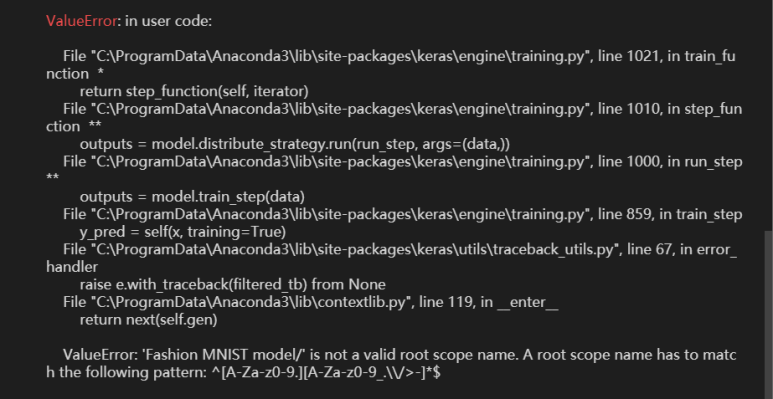
어? 오류가 난다. 설정한 이름에 문제가 있었나본데, 패턴매칭 실패다. 정규표현식을 자세히 보자.
"ValueError: 'Fashion MNIST model/' is not a valid root scope name. A root scope name has to match the following pattern: ^[A-Za-z0-9.][A-Za-z0-9_.\\/>-]*$"
정규표현식(Regex)은 일종의 체다. 언제까지고 자르기(슬라이스), 대소문자 검출, 숫자 꺼내기 등을 사용할 수만은 없다. 당장 C++만 해도 string::substring(), istringstream >>, isspace() 등등 얼마나 많은 함수가 필요한가. 정규표현식은 이런 문제를 한 방에 날려준다.
^[A-Za-z0-9.][A-Za-z0-9_.\\/>-]*$정규표현식에 대한 자세한 문법은 기술하지 않겠다만, 상황이 상황이니만큼 해석할 수 있는 정도만 하도록 하겠다. 이해가 된다면, 조금씩 떼어내는 방향으로 가겠다. 우선, ^은 문자열의 시작, $은 문자열의 끝을 뜻한다. 즉, 시작과 끝을 나타내는 기호다. 오케이. 패스.
[A-Za-z0-9.][A-Za-z0-9_.\\/>-]*대괄호는 해당 괄호 안에 있는 무엇이든지 '하나'를 잡겠다는 뜻이다. []안에 보면 A-Za-z0-9.이 있다. 하이픈 좌우를 기준으로 끊어서 보면 된다. { A-Z | a-z | 0-9 | . } 알파벳 대소문자 또는 숫자 또는 구두점(.) 중 아무거나 하나 있으면 된다. 오케이. 패스.
[A-Za-z0-9_.\\/>-]**은 앞에 있는 게 0개 이상이면 된다는 뜻이다. 오케이. 패스.
[A-Za-z0-9_.\\/>-]참고로 여기서 \(역슬래시)가 \\로 두 번 쓰였다. 다시 나누어서 보면, 다음과 같다.
{ A-Z | a-z | 0-9 | _ | . | / | > | - } 똑같이 알파벳 대소문자/숫자/. 이외에도 _ / > -등 더 다양한 문자를 지원한다. 오케이. 완료.
아까 모델 이름을 'Fashion MNIST model'으로 정했다. 그런데, 여기엔 공백이 있다. 위 정규표현식에서 공백을 인정했던가? 아니다. 그래서, 모델 이름을 바꿔주면 된다.
model = keras.Sequential(name='my-model')
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'))
model.add(keras.layers.Dense(10, activation='softmax', name='output'))
# 확인용
print('인공신경망 모델 확인')
model.summary()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)모델 이름을 my-model로 바꾸고 훈련을 다시 해보았다.
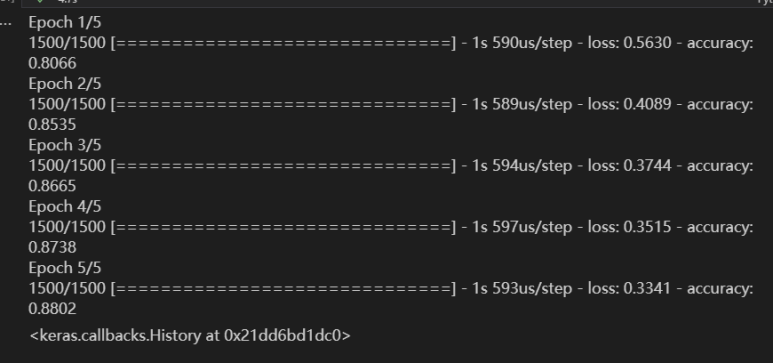
정상적으로 훈련이 된다. 이번에는 은닉층을 5개로 늘려보겠다.
model = keras.Sequential(name='my-model')
model.add(keras.layers.Dense(400, activation='sigmoid', input_shape=(784,), name='hidden1'))
model.add(keras.layers.Dense(300, activation='sigmoid', name='hidden2'))
model.add(keras.layers.Dense(220, activation='sigmoid', name='hidden3'))
model.add(keras.layers.Dense(150, activation='sigmoid', name='hidden4'))
model.add(keras.layers.Dense(90, activation='sigmoid', name='hidden5'))
model.add(keras.layers.Dense(10, activation='softmax', name='output'))
# 확인용
print('인공신경망 모델 확인')
model.summary()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)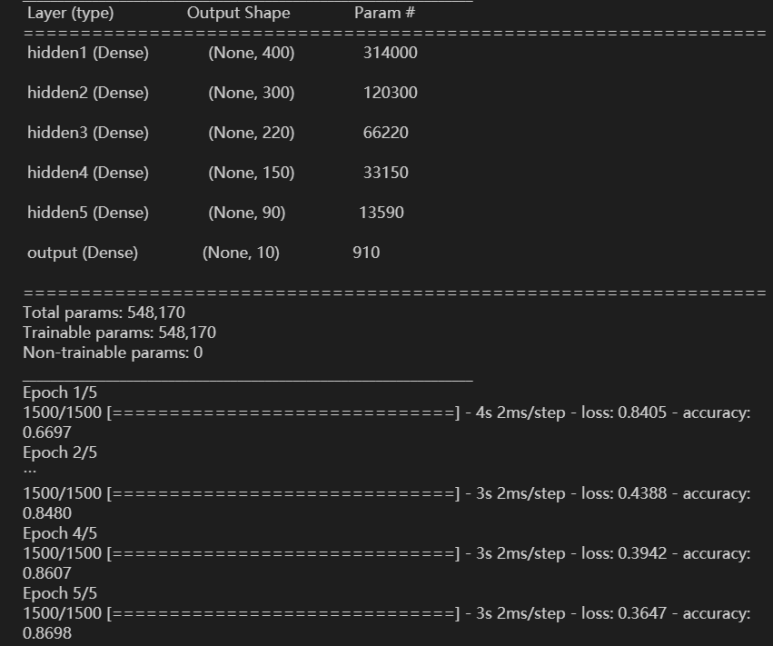
정확도는 비슷비슷하다. 그런데 첫 에포크의 정확도는 오히려 감소했다. 층의 개수를 바꿔가며 3층, 2층으로 구현해보니 오히려 층이 줄어들수록 정확도가 올라갔다. 이건 왜일까.
글이 길어지니 적당히 끊고, 다음에서 이어서 하겠다.
'머신러닝 & 딥러닝' 카테고리의 다른 글
| 머신러닝 대표 알고리즘의 종류: 선형 회귀, 로지스틱 회귀, 결정 트리, K-최근접 이웃 회귀 (0) | 2022.05.29 |
|---|---|
| C# 머신러닝 프로젝트: NOCHES 멤버의 말투를 잡아라! (0) | 2022.02.20 |
| 머신러닝&딥러닝 기초(5): 결정 트리, 교차 검증과 그리드 서치, 앙상블 (0) | 2022.02.17 |
| 머신러닝&딥러닝 기초 (4): 머신러닝 기초 다지기 (0) | 2022.02.17 |
| 머신러닝&딥러닝 기초(3): 회귀분석 (0) | 2022.02.15 |