이진 분류에는 트리가 제격이다. 두 가지의 애매한 것들이 있을 때, 이진 트리를 분류할 수 있다. 이때 트리는 위에서 아래 방향으로 진행되며, 조건식이 참인 경우 왼쪽으로, 거짓인 경우 오른쪽으로 진행된다. 보통 자료 저장용 트리의 경우엔 값이 작으면 왼쪽으로, 크면 오른쪽으로 저장된다. 그러나 머신러닝에서의 결정 트리는 약간 다르다. 지금 보면 트리 내부에 조건식이 하나 달려있다. 이것을 토대로 조건식이 참인 노드는 왼쪽으로, 거짓인 노드는 오른쪽으로 파생된다.


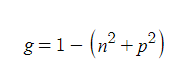
어느 한 쪽에 클래스가 치우칠수록 gini 불순도는 0에 가까워진다. 0에 도달하면 순수 노드가 된다. 결정 트리는 parent node와 child node의 값이 가장 크도록 생성된다.
부모의 불순도 - (왼쪽 노드 샘플 수 / 부모의 샘플 수) * 왼쪽 노드 불순도 - (오른쪽 노드 샘플 수 / 부모의 샘플 수) * 오른쪽 노드 불순도
이 값을 계산하는 거다. 이 차이를 정보 이득, information gain이라고 하는데 결정 트리는 정보 이득이 최대가 되도록 데이터를 분류하는 것으로 볼 수 있다. 하지만 제한 없이 생성되기만 하면 역시나 overfitting 문제가 발생한다. 일반화가 잘 적용되지 않는 셈이다.
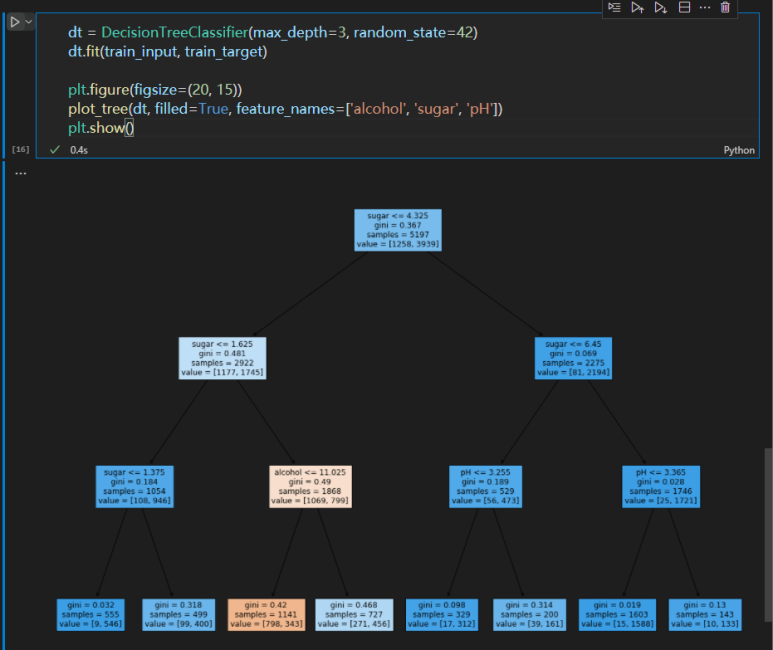
결정 트리의 경우 데이터를 표준화할 필요가 없다. 그래서 굳이 StandardScaler을 이용해서 전처리를 거칠 필요가 없다. 아니, 오히려 전처리를 하면 데이터가 이상해보인다. 여하튼, 트리를 이렇게 계속 이용하다보면 테스트를 많이 거쳐야 하는데, 그럼 결국 test set에 맞는 모델이 만들어질 뿐이다. 그래서 등장하는 개념이 교차 검증이다. 우선, 우리가 그동안 사용했던 train set과 test set에 이어 validation set(검증 세트)를 추가로 생성해야 한다. 그렇다면 여기서 또 split 함수를 사용하게 되겠지.
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42) # 0.2 = 테스트 세트의 비율
sub_input, val_input, sub_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42) # 0.2 = 검증 세트의 비율이런 식이다. 그럼 이제 나누어진 세트들을 가지고 검증을 반복해야 한다.
K겹 교차검증이란 게 있다. 전체 데이터를 K개로 나눈 뒤, (K-1)개로 학습을 진행한다. 나머지 한 개로 검증을 진행한다. 그렇게 계속 다른 세트를 골라서 (kC(k-1) 같은 느낌이랄까) K번 학습을 반복한 뒤, 검증 점수의 평균을 구하면 된다. 이걸 다른 말로 k-폴드 교차 검증이라고도 한다. 세 부분으로 나누면 3-폴드 교차 검증이 된다(3-fold cross validation). 보통은 5나 10을 많이 사용한다.

그렇다면 데이터를 우리가 일일이 10개로 쪼개야 하는가? 하면 그런 것은 아니다. 이미 사이킷런에서는 훌륭한 메서드를 제공한다. cross_validate인데, StratifiedKFold()를 이용해 K값을 정할 수 있다. n_splits 파라미터의 값이 K값이다. 기본값은 5, 아래의 경우 명시적으로 10을 기술했으니 10-fold cv를 진행한다.
하이퍼파라미터hyperparameter란, 머신러닝 모델에게 인간이 직접 넘기는 파라미터를 뜻한다. 머신러닝 모델이 학습하는 parameter은 model parameter인데, hyperparameter은 학습할 수 없는 것들이다. 이것들을 바꿔가면서 계속해서 교차 검증을 해나가야 한다. 물론, 이 파라미터는 동시에 다뤄야 한다. 편미분 하듯 하나 바꾸고 고정시키고 다른 거 바꿀 수 있는 게 아니다. 종속적이다.
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target) # params에 지정한 만큼 train
dt = gs.best_estimator_ # 가장 좋은 모델
print(gs.best_params_)
best_index = np.argmax(gs.cv_results_['mean_test_score'])
gs.cv_results_['params'][best_index]그나마 다행인 건, 이걸 알아서 결정해주는 클래스가 있다는 것. 탐색할 매개변수를 정하고, train set에서 grid search를 진행한다. 가장 좋은 mean_test_score가 나오는 경우 이 조합은 그리드 서치 인스턴스에 저장된다. 그 다음 가장 좋은 매개변수에서 전체 train set을 이용해 모델을 훈련시킨다.
params: dict = {
'min_impurity_decrease' : np.arange(0.0001, 0.001, 0.0001),
'max_depth' : range(5, 20, 1),
'min_samples_split' : range(2, 100, 10)
}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
gs.best_params_이 알고리즘에 의하면 대략 6~7000개의 모델을 만들었다 빠갰다 한다. 이걸 사람이 한다고 생각해보자. .....어우. 생각하지 말자.
from scipy.stats import uniform, randint
params = {
'min_impurity_decrease' : uniform(0.0001, 0.001),
'max_depth' : randint(20, 50),
'min_samples_split' : randint(2, 25),
'min_samples_leaf' : randint(1, 25)
}
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params,
n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)
gs.best_params_만약 아무 것도 모르겠다면 그냥 랜덤함을 부여하면 된다. 가급적이면 이제 hyper-parameter은 그리드 서치 객체에게 맡기자.
랜덤 포레스트(Random Forest)
구조화된 데이터를 structured data라고 부른다. (정형 데이터) 말 그대로 structure가 갖춰 있는 데이터다. 엑셀에 사용하면 딱이다. 그런데, 이와 반대되는 걸 unstructured data라고 한다. 비정형 데이터인데, 쉽게 말해 엑셀에 넣기 힘든 것들을 나타낸다. 사진, 영상, 음악 등. Structured data에는 Ensemble learning이 제격이다. 가장 뛰어나다. 반면, Unstructured data에는 신경망, 즉 딥러닝을 이용해야 한다.
Random Forest는 결정 트리로 만든 숲이다. 각 결정 트리의 prediction을 이용해 최종 예측을 만든다. train set에서 랜덤하게 sample을 끌어다가 훈련 데이터를 만든다. 중복도 가능하다. 이렇게 만들어진 샘플이 bootstrap sample이다. train set과 크기가 같다.
train-set = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
bootstrap-sample1 = [2, 4, 7, 4, 3, 9, 1, 7, 3, 4] # 무작위
bootstrap-sample2 = [1, 6, 4, 2, 4, 6, 8, 9, 10, 2]
bootstrap-sample3 = [7, 6, 5, 7, 8, 9, 5, 4, 6, 7]
.
.이런 식이다. 그리고 각 트리에서는 특성을 무작위로 고르고 최선의 분할을 찾는다. 그런데 이렇게 '무작위'로 고르다보면, 남는 것들이 분명 있지 않을까? 그렇다. 이것들을 OOB, out-of-bag sample이라고 한다. 마치 test set과 같은 역할을 할 수 있다.
rf = RandomForestClassifier(oob_score=True, n_jobs=-1, random_state=42)
rf.fit(train_input, train_target)
rf.oob_score_이렇게 하면 교차 검증을 대신할 수 있다.
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs=-1)
np.mean(scores['train_score']), np.mean(scores['test_score'])엑스트라 트리extra tree라는 것도 있는데, 이건 bootstrap 샘플을 사용하지 않는다. 대신, 트리 노드 분할시 이걸 랜덤으로 분할한다. 이건 더 많이 훈련을 하긴 해야 하는데, 그래도 빠른 게 장점이다.
'머신러닝 & 딥러닝' 카테고리의 다른 글
| C# 머신러닝 프로젝트: NOCHES 멤버의 말투를 잡아라! (0) | 2022.02.20 |
|---|---|
| 머신러닝&딥러닝 기초(6): 처음 만드는 인공신경망 (0) | 2022.02.17 |
| 머신러닝&딥러닝 기초 (4): 머신러닝 기초 다지기 (0) | 2022.02.17 |
| 머신러닝&딥러닝 기초(3): 회귀분석 (0) | 2022.02.15 |
| 머신러닝&딥러닝 기초(2): 머신러닝의 학습과 편향 (0) | 2022.02.13 |