환영합니다, Rolling Ress의 카루입니다.
어제 좀 삼천포로 빠졌죠. 다시 마음 잡고.
머신러닝의 알고리즘은 supervised learning(지도 학습)과 unsupervised learning(비지도 학습)으로 구분된다. 지도 학습은 training data(훈련 데이터)가 필요한데, input(입력 데이터)과 target(타깃 정답)으로 구성된다. 그리고 각 요소를 구분해주는 것들을 feature이라고 한다. Supervised learning은 target을 '맞추는' 것을 목표로 학습한다. Unsupervised learning의 경우 target, 즉 정답이 없으므로 맞추는 게 아니라 데이터 파악 및 변형에 사용된다. 데이터를 구했는데 정답target이 없다면, 비지도 학습을 사용한다.
**교과연계(2학년 심화영어Ⅰ): 이 외에도 머신러닝 알고리즘에는 reinforcement learning(강화 학습)이 존재한다. It's known as 'Instrumental/Operant Conditioning Learning’. The algorithm will get either positive or negative reinforcement for its behaviors. Reinforcement learning, that is, can “train” the machine learning algorithm by giving them corresponding rewards.
이제 공부를 시작했는데 Reinforcement Learning까지 가면 분명 내 머리가 터질 것이다. 스킵하고 넘어가도록 하자. 아무튼, 지금까지 나온 것들의 관계를 정리해보자면...
namespace ArtificialIntelligence
{
class MachineLearning
{
Learning SupervisedLearning() = new() { new kNearestNeighbors(); };
Learning UnsupervisedLearning();
Learning ReinforcementLearning();
}
class DeepLearning : MachineLearning
{
}
} C# 의 클래스로 나타내보면 이런 관계다. 사실 Inheritance(상속)을 여기서 사용하는 게 적절하진 않을 것 같은데, 이걸 is-a relationship으로 봐야할지, has-a relationship으로 봐야할지는 애매하다. 그래도, 'DeepLearning is-a MachineLearning'은 참이고, 'MahineLearning is-a DeepLearning'은 거짓이므로 is-a가 맞는 것 같긴 하다. 코딩 몇 번 하다보면 다이어그램보다 소스코드가 더 편하다. 클래스뷰는? 안써요.
머신러닝을 다룰 때 중요한 것은 train set과 test set이 달라야 한다는 것이다. train set은 말 그대로 train을 할 때 사용한 데이터셋이다. test set은 그걸 검증하는 데 사용하는 데이터셋이다. 예시를 들어보자. 2학년 창의적문제해결기법 시간에 사용한 'Teachable Mahine' 사이트를 가져와봤다.
Teachable Machine
Train a computer to recognize your own images, sounds, & poses. A fast, easy way to create machine learning models for your sites, apps, and more – no expertise or coding required.
teachablemachine.withgoogle.com
위 사이트에 들어가서 이미지를 학습시키자.
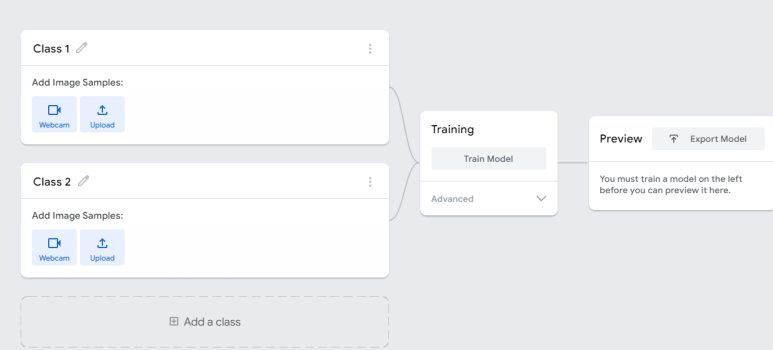
이렇게 페이지가 뜬다. 클래스룸에서 받은 실험데이터를 토대로 호랑이와 사자를 구분하도록 학습시켜보자. 여기서 사용할 것은 train set이다.

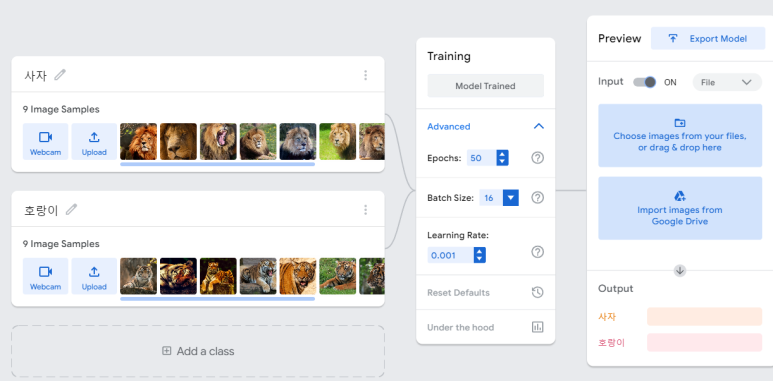
일단 보면 알겠지만, 여기서도 binary classification을 할 것이다. train set이 준비되었다면 Train Model 버튼을 눌러 학습시키자. 학습이 끝나면 오른쪽 처럼 뜨는데, 이제 Preview 창에서 train set의 데이터 중 아무거나 하나를 업로드해보자.
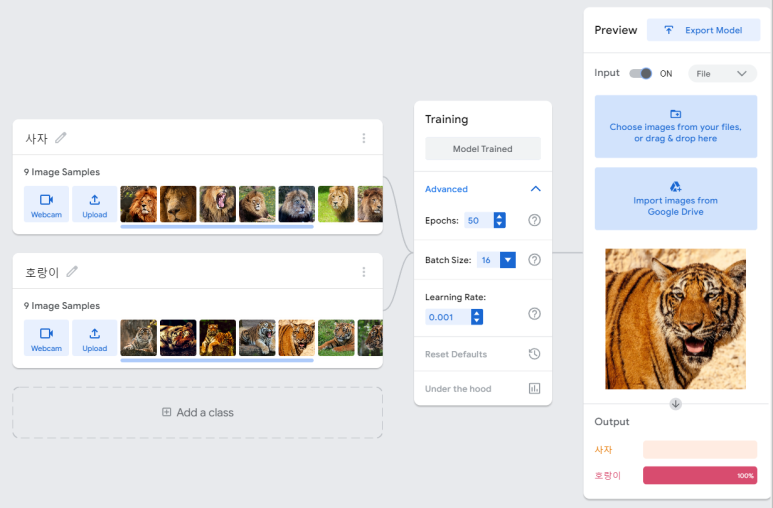
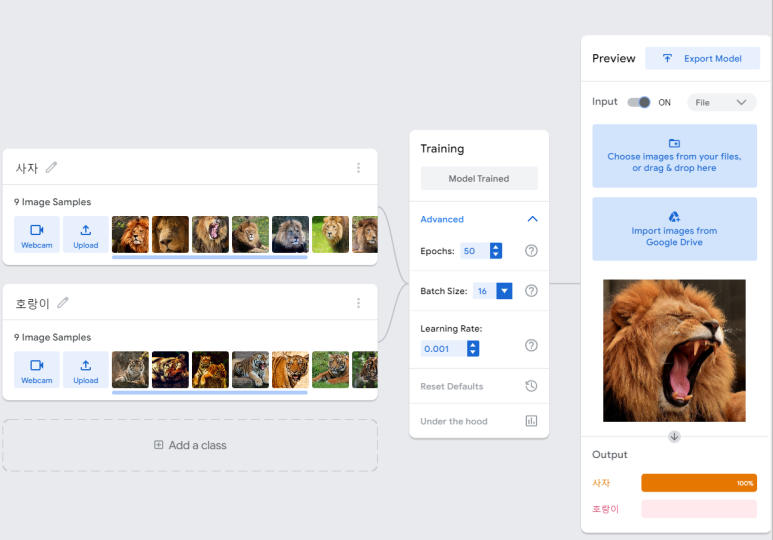
호랑이 100%가 뜬다. 당연하지! 이건 내가 답을 준 거니까. 그래서 이미 target으로 사용된 train set으로 테스트하는 것은 아무런 의미가 없다. 이제 test set의 데이터를 사용해보자. 대체로 정확도가 높다. 특히나 여기선 입까지 쩌억 벌리고 있으니까.


그런데, 사자랑 호랑이를 헷갈린다. 이거 둘 다 사자다. 암사자. 그런데 train set으로 사용한 데이터 중에서는 암사자가 없다. 갈기가 없으니, 이걸 멋대로 호랑이라고 판단한 것이다. 이래서 train set이 중요하다. 다만, 나는 training의 옵션을 살짝 손대어 정확도를 높여볼 것이다.

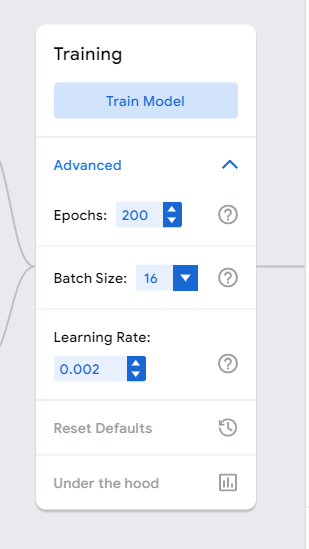


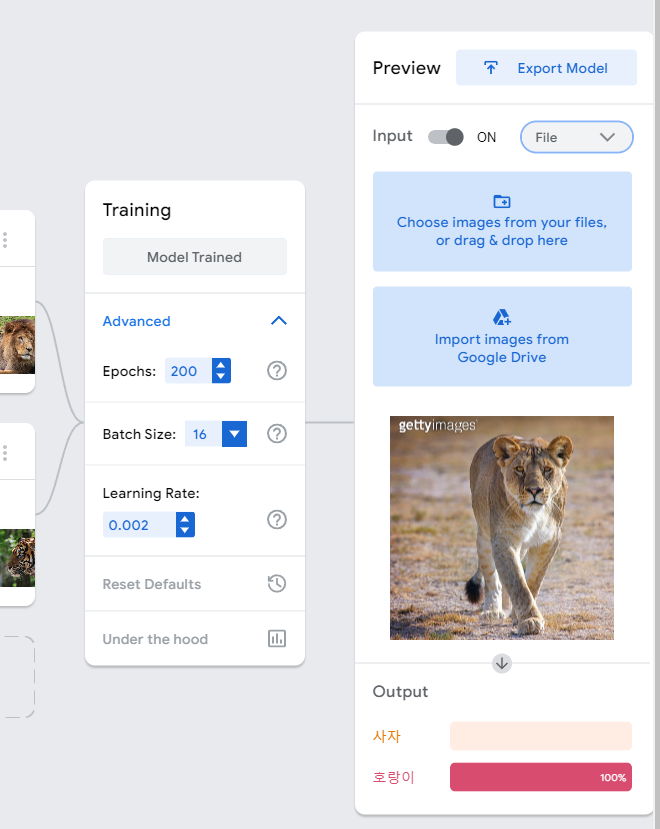
이젠 아예 호랑이라고 확신을 가져버린다 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 미치겠네...
이것을 sampling bias, 샘플링 편향이라고 부른다. 인공지능에서는 이 bias가 집요하게 작용한다. 이것때문에 독서 시간에 '인공지능과 법' 발표하면서도...
(독서 때 사용한 책이 역사를 움직이는 힘, 정체성과 폭력, 인공지능과 법 이 세 가지인데, 저 중 하나만 구글에 검색해도 다른 게 연관으로 뜬다고 합니다...고양국제고 정말 대단해! 허허ㅓㅓ)
아무튼, 인공지능과 법 읽으면서 발표할 때도 bias에 대해 엄청난 논쟁을 벌였다.

창문해 때도 비슷한 논지를 펼쳤다. 인공지능이 가지는 편향은 두 종류인데, 하나는 인간 사회의 편향을 학습해서 발생하는 대표성 편향과 알고리즘 자체의 문제 혹은 편향된 데이터의 문제로 발생하는 알고리즘 편향이 있다. 지금 발생하는 건 알고리즘 편향, 그 중에서도 샘플링 편향이다.
여하튼, 파이썬에서도 무작정 list를 append시키면 저런 문제가 나타날 수 있다. 잘 섞어줘야 하는데, 그게 안 된다는 거다. 그래서 사이킷런에서는 train_test_split을 제공한다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
data, target, stratify=target, random_state=N)random_state는 필요 없으면 생략해도 된다. 그럼 Random seed가 자동으로 설정된다. 필요한 경우엔 N 자리에 적당한 수를 대입하면 된다. 아무튼, 해당 메서드? Constructor?을 통해 다중 반환을 받으면 데이터를 바로 사용할 수 있다.

그럼 그냥 이렇게 적당히 사용할 수 있는 셈이다.

어제 머신러닝 기초랍시고 상당히 뻘짓을 했는데, 이게 맞다. 데이터 전처리가 안 되어 있으니 분류가 엉망으로 되는 건 당연하다. 책만 보고 팠는데...음....
그래, 가르치는 사람들의 흔한 변을 짐작하지 못한 내 탓이다. 프로그래밍이야 워낙 내 강점이다보니 따라가는 속도는 빠른데, 인공지능에 대한 지식은 전무하다보니 과속하다가 구렁텅이에 빠져버린 셈....그래..이러면서 배우는 거지.....좋아ㅏ.....크크크큭....

그래서 좌표계의 x, y값을 적절히 변환하는 과정이 필요하다. 이걸 데이터 전처리라고 하겠다. -1.5부터 1.5까지, 1:1의 비율로 나타났다.
분산: (변량 - 평균)²의 총합 / 변량 개수
표준편차: sqrt(분산)
표준점수: 각 데이터가 원점에서 몇 표준편차만큼 떨어졌는지
를 나타내는 것들이다.
글이 길어져서 이만 끊겠습니다. 이제 회귀분석까지 나가야 하는데....사탐방...빠드득... 다음에 보죠 :)
'머신러닝 & 딥러닝' 카테고리의 다른 글
| 머신러닝&딥러닝 기초(6): 처음 만드는 인공신경망 (0) | 2022.02.17 |
|---|---|
| 머신러닝&딥러닝 기초(5): 결정 트리, 교차 검증과 그리드 서치, 앙상블 (0) | 2022.02.17 |
| 머신러닝&딥러닝 기초 (4): 머신러닝 기초 다지기 (0) | 2022.02.17 |
| 머신러닝&딥러닝 기초(3): 회귀분석 (0) | 2022.02.15 |
| 머신러닝&딥러닝 기초 (1): 머신러닝 기초를 배우며... (0) | 2022.02.13 |