환영합니다, Rolling Ress의 카루입니다.
이 카테고리는 제가 책을 읽으면서 내용을 정리하는 곳으로 쓸까 해요. 나중에 제가 다시 찾아볼 수 있게끔...사탐방 딱 대 남들이 설문돌릴 때 나는 코퍼스와 빅데이터로 승부한다
자, 시작하죠.
인공지능artificial intelligence의 정의는 단순하다. 인공적인 지능. 끝.
그런데 그 뒤에는 훨씬 복잡한 것들이 자리하고 있다. 인공지능을 "어떻게" 만들 것인가? 인공지능은 그동안 발전을 거듭하며 마치 우리가 투자한 주식처럼 떡락과 떡상을 반복했다.
인공지능에는 두 가지 종류가 있다.
- 강인공지능(일반인공지능): 영화 속 인공지능. 인공지능이 정말 인간처럼 행동하는 것
- 약인공지능: 아직까지, 현실의 인공지능. 인간 보조 역할밖에 할 수 없다.
머신러닝이란, 알아서 데이터 학습 알고리즘을 연구하는 분야다. 인공지능의 하위로, 지능 구현 소프트웨어를 담당한다. 딥러닝은 머신러닝 중 인공신경망을 기반으로 동작하는 것들이다. 이 셋의 관계를 표현하자면,
'인공지능 :: 머신러닝 :: 딥러닝'인 셈이다 ( '::' 는 '⊃' 기호와 같은 의미다. C++에서...)
머신러닝에서는 사이킷런, 딥러닝에선 텐서플로가 대표적인 lib으로 존재한다.
데이터 마이닝data mining, 빅데이터big data, 데이터 과학data science는 모두 큰 맥락의 인공지능에 포함된다. 괜히 인공지능과 빅데이터를 연관짓는 게 아니다. 비교문화 시간에 4차산업 발표하면서 빅데이터 연관짓길 참 잘한 것 같다. 이과생 멱살캐리...응?

바로 실전으로 들어가보자. 사실 난 파이썬을 그다지 좋아하지 않는다. 인터프리터 언어라 짜증나는 것도 있고 (얼마 전만 해도 static type definition이 안 되지 않았는가!) 무엇보다 나에게는 나를 개발자로 만들어준 C# 이 있지 않는가. 고양국제고를 뒤집어놓은 GGHS Time Table. C# 과 XAML 조합으로 만들어졌다.
여하튼, 나는 코랩이 싫다. 너무 비전문가틱하다. 학교에서 애들 잠깐 가르치는 데엔 코랩을 써도, 어차피 내 본진은 프로그래밍인데? 그리고 나처럼 한번이라도 실무 개발을 겪은 사람이라면... vs 안 깔린 사람이 없을 거다. 그래, Visual Studio랑 Code까지 다 깔아두자. 이참에. 그 함부로 VS 깔라고 하다가는....용량이 쿨럭
이제부터는 용어를 영어로 먼저 설명하고, 한국어는 처음 나올 때만 괄호에 설명하겠다. 아는 사람은 알겠지만 이쪽 분야에서는 영어로 바로 이해하는 게 더 쉽다. 생각해보라. 딥러닝이 더 익숙한지, 심층학습이 더 익숙한지.
Machine Learning(이하 ML)에 대해 조금 더 자세히 알아보자. Class(종류) 중 하나를 구별하는 것을 classfication(분류)이라고 한다. 이때, 두 개의 class에서 classification을 하는 것을 binary classification(이진 분류)라고 한다. unary/binary operator의 그 binary 맞다.
각 데이터에는 특징이 있다. 이것을 해당 데이터의 feature이라고 하자. 특성...으로 볼 수도 있는데, attribute도 똑같이 특성으로 번역되기 때문에 헷갈린다. 속성이라고 하지 마라... 영어를 쓰는 이유도 이것 때문이다. 한국어가 가끔 겹치더라.


슬슬 시동을 걸어본다. 오른쪽과 같은 scatter plot(산점도)이 나온다. 이 점들을 잘 옮기면, 마치 y=x같은 직선이 나올 것 같다. 직선...선.. 선형. 일차함수. 이런 걸 linear라고 한다. 선형적.

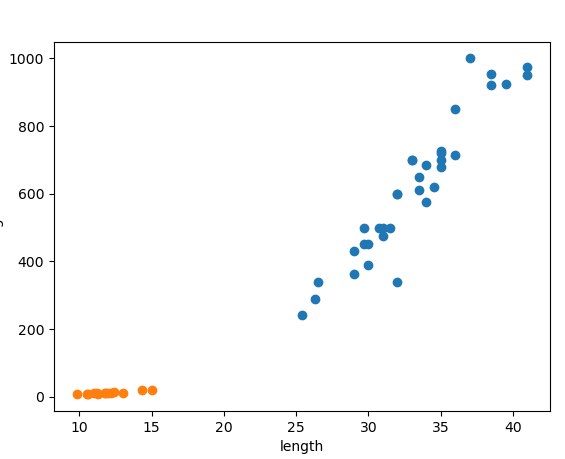
아직 matplotlib의 동작 원리를 잘 모르겠다. 한 가지 확실한 건, plt로 import 시킨 후 여러 주제의 scatter plot을 그리고 싶다면 그냥 scatter()을 여러 번 호출하면 된다.
k-Nearest Neighbors
k 최근접 이웃... 이건 뭐 K-방역도 아니고 뭘까 이게. 아마 이름만 들어선 서로 속한 것들끼리 묶는 것 같다. 위 그래프만 봐도 주황색과 파란색이 떨어진 모습이 보이지 않는가.
파이썬에서는 for을 참 이상하게 쓴다. 이건 그냥 뒤에서부터 풀어서 해석하면 편하다. 여기서 x_data, y_data가 list일 경우, 해당 list들을 iterate하며 묶어서 꺼낸다. for은 이걸 반복하는 일을 한다. 그럼 zip() 함수가 x_data, y_data를 묶어서 주면 for은 계속 반복하면서 전달하고, 그걸 [x, y]의 새로운 list로 저장한다. 그렇다면 data의 type은 뭘까? 2d list다.
자, 일단 머신러닝은 분류에서 출발하는 것 같다. 분류를 '학습'시키려면 일단 답을 알려줘야 한다. 노답 문제를 풀라고는 할 수 없지 않는가.
(단, n, m은 uint형 자연수, target은 list 인스턴스)
이렇게 하면 분류하고자 하는 것들을 검출할 수 있다. 여기서 1은 찾으려는 대상, 0은 그 외의 것을 나타낸다.
(단, kn은 sklearn.neighbors.KNeighborsClassifier 타입 인스턴스)
그럼 자기가 알아서 training(훈련)한다. score() 메서드는 학습의 결과, accuracy(정확도)를 반환한다. 0부터 1.0까지.
KNeighborsClassifier의 constructor에 n_neighbors 라는 파라미터를 이용해 자연수를 대입해주면 참고 데이터의 수를 변화시킨다. (default는 5다)
기존에 다른 책을 읽으면서, binary classification은 두 데이터를 말끔히 자르는 선이 뚜렷하고, 데이터의 표본들이 그 선에서 멀리 떨어질수록 좋다고 들었다. 그렇다면, 이 데이터들을 말끔히 자르는 직선을 구해보자.

대충 파워포인트로 그리려다가, 오기가 생겼다. 변량들을 메모장에 담아 csv로 저장한 후, Excel에서 피벗시킨다. 이걸 지오지브라에 입력하면, 이변량 회귀분석을 할 수 있다. 이 식을 대수창에 입력해보자.

편의상 x축을 길게 잡아 늘렸다. 이제 데이터가 좀 보인다. 이 둘에서 가장 멀리 떨어진 직선을 어떻게 구할 수 있을까? 잘 모르겠다. 다만, 두 직선의 교점과 수직관계를 이용해보자. 빨간 선과 파란 선의 교점을 지나고, 각각 직선에 수직인 두 직선을 구해보자.


....? 당황스럽다. 내가 설마 고1 수학도 다 까먹은 건가...그럴 리가 없는데....
혹시나 싶어 x축을 원래 비율로 줄였다. .....이제 맞다. 아무튼, 이제 저 두 직선의 중간을 지나는 직선을 구해보자. 이것도 아마 수상에서 나오지 않나... 내가 기억을 하고 있을지 모르겠다.

그럼 이렇게 a, b에 관한 방정식이 나오는데, 이걸 풀어....야.....겠지....네가 선택한 길이다. 풀어라.
허억....허억....어쨌든 위와 같은 직선의 방정식이 하나 나왔다. 였는데 이런 Tlqkf......

지금 구한 건 저 보라색 직선이다. 다른 거다...다시 구해야 하는데....


어차피 수직이니까, 그냥 수직으로 구했다. 원노트의 자동 계산 덕택을 정말 많이 봤다.. 저거 없었으면 난 아마 풀다가 숨졌을거야. 아마도.


자...완성본이다. 이걸 왜 만들었는진 모르겠는데, 어쨌든 저렇다. 근데...이거 순수 수학으로만 만드는 게 아닌가보다 ㅋㅋㅋㅋㅋㅋㅋㅋㅋ하 짜증나네.... 아래 군집에 너무 가깝다. 기껏 에너지 쏟은 결과가 이거라.... 다음 번엔 좀 제대로 만들어봐야겠다.
머신러닝하다가 왜 지오지브라 붙잡고 끙끙대는지는 의문.
'머신러닝 & 딥러닝' 카테고리의 다른 글
| 머신러닝&딥러닝 기초(6): 처음 만드는 인공신경망 (0) | 2022.02.17 |
|---|---|
| 머신러닝&딥러닝 기초(5): 결정 트리, 교차 검증과 그리드 서치, 앙상블 (0) | 2022.02.17 |
| 머신러닝&딥러닝 기초 (4): 머신러닝 기초 다지기 (0) | 2022.02.17 |
| 머신러닝&딥러닝 기초(3): 회귀분석 (0) | 2022.02.15 |
| 머신러닝&딥러닝 기초(2): 머신러닝의 학습과 편향 (0) | 2022.02.13 |